Synapse – Creación de Data Warehouse sin servidor
Reproducimos el caso de éxito de Afimilk publicado en el Blog de Azure Synapse Analytics porque pensamos que es interesante también para nuestro clientes.
Afimilk es un pequeño proveedor independiente de software (ISV) que ofrece soluciones para explotaciones lecheras para ayudar a los ganaderos a determinar el momento óptimo de inseminación de las vacas para aumentar la producción de leche. Se buscaba una forma rentable de recopilar datos de las explotaciones lecheras, limpiarlos y organizarlos, y permitir a los científicos de datos utilizarlos para construir mejores modelos.
Requisitos de Afimilk
- Miles de fuentes de datos similares, con baja tasa de cambio
- Más de 3000 fuentes, con < 20 pequeños archivos diarios por ubicación
- Rentable
- Utilizar computación sin servidor siempre que sea posible
- Utilizar repositorios de datos de bajo coste
- La frecuencia de actualización horaria es suficiente
- Facilidad de operación, ya que el número de recursos puede aumentar, se requiere un modelo operativo sólido.
La solución: Un data warehouse sin servidor
Se creó una solución rentable abordando áreas de implementación como la construcción del entorno utilizando IaC (infraestructura como código), o el uso de acciones/actividades DevOps para desplegar la solución.
Tecnología
- Pipelines de Synapse – orquestador
- Azure Storage con soporte de espacio de nombres jerárquico – almacén de datos principal
- Formato de datos – Parquet (los archivos originales eran archivos JSON – JavaScript Object Notation – comprimidos)
- Azure Function – proporciona una solución rentable para el procesamiento de archivos individuales
- Power BI – visualización de datos
- DevOps – combinación de scripts de Bicep y acciones de GitHub
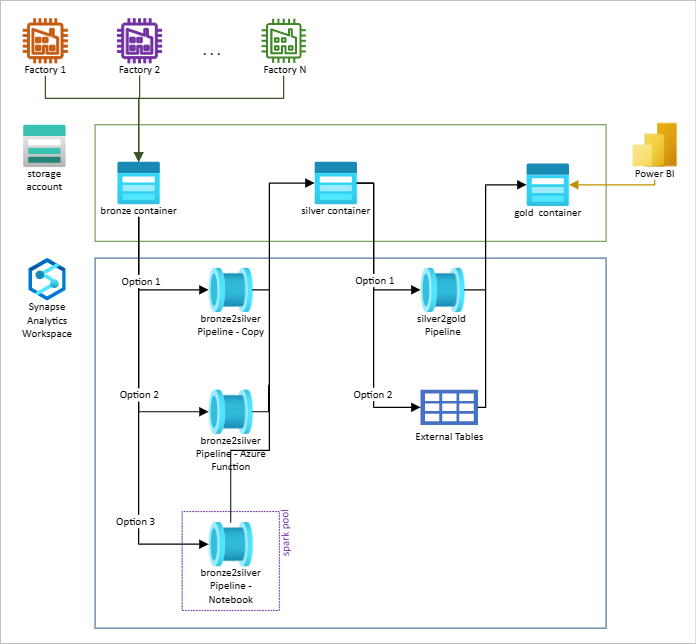
Solución tecnológica
Contenedor Bronce a Contenedor Plata
- Actividad de copia: una actividad de copia leerá una tabla de control y se utilizará para mover los archivos sin procesar del contenedor bronce (bronze) al contenedor plata (silver). Ideal cuando no se aplica ninguna lógica de negocio.
- Función Azure – Una función Azure leerá una tabla de control y se utilizará para mover los archivos no procesados en el contenedor bronce (bronze) al contenedor plata (silver) después de aplicar alguna lógica de negocio compleja.
- Notebook – Igual que azure function pero ideal para grandes cantidades de datos.
De contenedor Plata al contendor Oro
- Store Procedure – Se utilizará un procedimiento almacenado sin servidor para crear los resultados agregados.
- Tablas externas – Se utilizarán tablas externas para crear los resultados agregados.
Puntos clave
- Para minimizar los costes al utilizar Synapse o Azure Data Factory, es aconsejable evitar las actividades individuales (por archivo) y repartir los datos en un número mínimo de archivos más grandes (idealmente, de 200 MB o más).
- Cuando se trabaja con muchos archivos pequeños, el rendimiento puede mejorar en plataformas como Databricks y Serverless SQL utilizando archivos más grandes.
- Managed VNet (Virtual Network) Integration Runtime puede no ser la opción más eficiente o segura para todos los usuarios, especialmente para aquellos con un menor volumen de datos y actividades. En estos casos, hay que considerar la posibilidad de utilizar Integration Runtime autoalojado, que permite personalizar el tamaño de las VM (máquinas virtuales), las horas de funcionamiento y la postura de seguridad de la red.
FUENTE: Synapse – Creating a serverless Data Warehouse (Azure Fastrack team)